
" height="30.471000000000007px" id="kLb0q0ygP" width="213.9970041503906px"/></g></svg>)
" height="30.471000000000007px" id="rJCF8bfz0" width="32.522000000000006px"/></svg>)
Brett Levenson-Arkin

For two decades, the org chart of a Trust and Safety team has looked roughly the same. A small core of full-time policy and operations staff at headquarters, sitting atop a pyramid of contracted reviewers—often thousands of them—distributed across human review teams (typically via BPOs) in Manila, Hyderabad, Lisbon, Austin. The full-timers wrote policy; the contractors enforced it, one ticket at a time, at volumes no in-house team could possibly absorb.
This shape wasn't an accident. It was the only way the math worked. Content might scale super-linearly with users, but headcount couldn't. And thus, the work got pushed outward and downward—to vendors with thinner margins, to reviewers with less context, to workflows optimized for throughput over judgment. Everyone who has worked in safety or integrity knows the costs of this arrangement. The reviewer mental health crises that periodically surface in the press. The "policy drift" that happens when the people enforcing rules sit six time zones and three subcontracting layers away from the people who wrote them. The quality variance that no amount of calibration training fully closes.
We accepted all of this because we didn't have an alternative. We have one now.
The AI systems available today can do the work that human review pyramids were built to do. Not perfectly, and not unsupervised—but well enough, fast enough, and at a marginal cost low enough that the economic reason for the pyramid has collapsed. A single AI evaluation pipeline, properly configured, can do in seconds what a queue of moderators does in hours, and it can do it without burnout, without attrition, and without the latency of training someone new every time policy shifts.
The instinct in most T&S orgs right now is to use this capability to do the same thing cheaper. Reduce BPO contracts. Lower per-review costs. Keep the shape, shrink the base. This is the wrong move, and I think it will be obvious in retrospect that it was the wrong move.
The right move is to invert the pyramid.
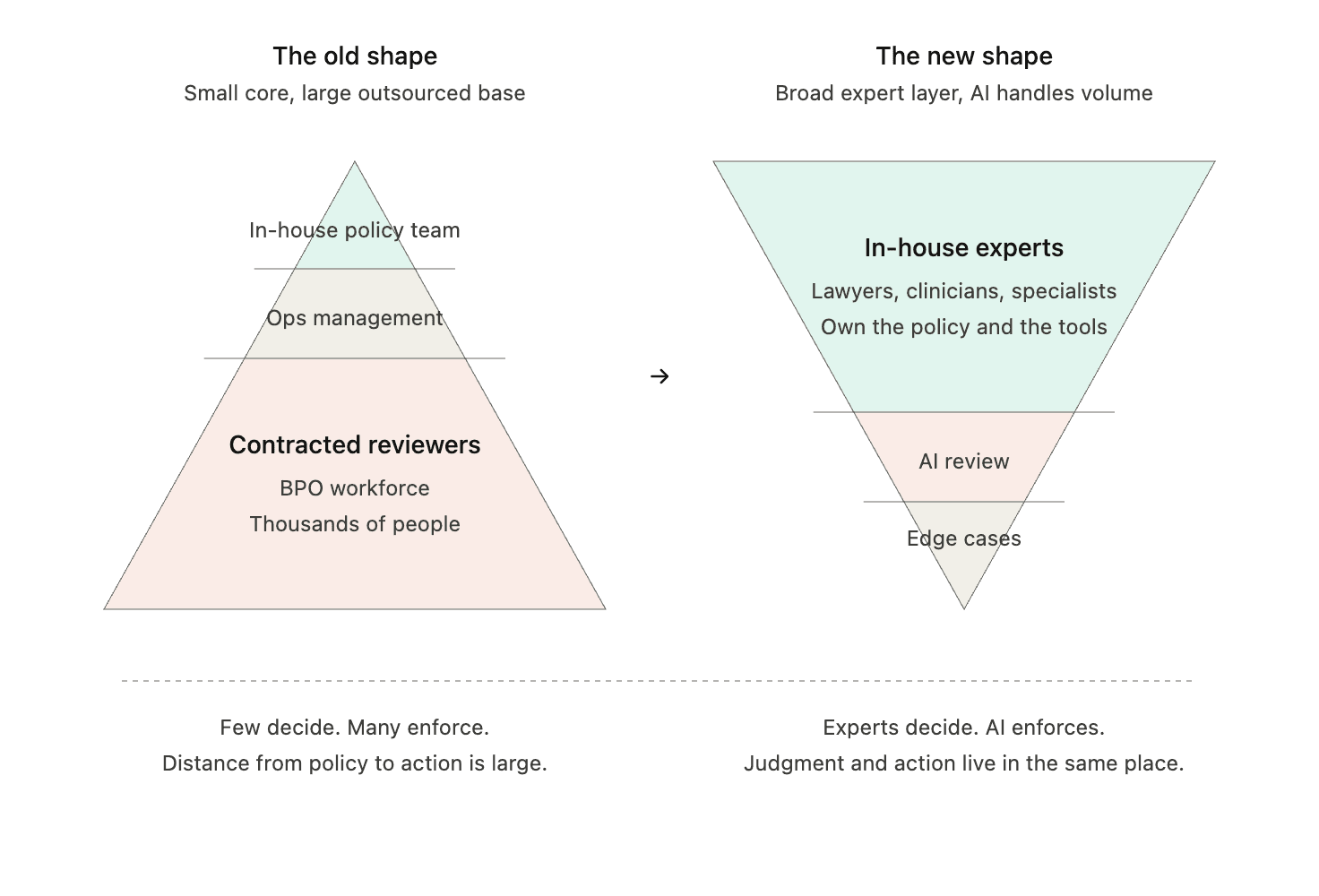
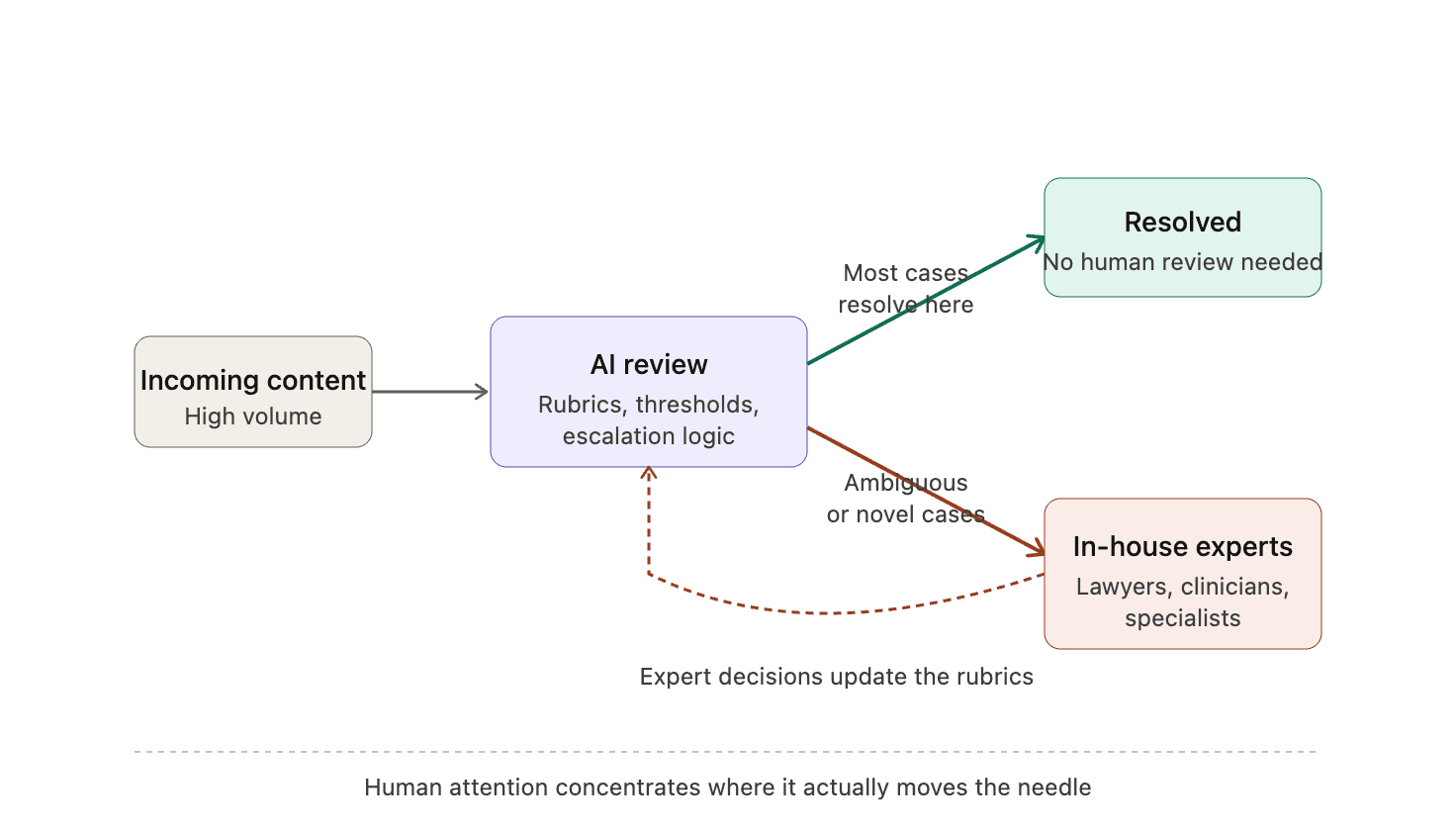
Bring the work back in house. Not the volume—the AI handles that. Bring back the judgment. Hire subject matter experts: lawyers for legal-adjacent content categories, clinicians for medical and mental health, financial compliance professionals for regulated communications, child safety specialists, election integrity experts, linguists for under-resourced markets. Pay them well, give them job security, and put them in control of the AI systems doing the review. They write the rubrics. They tune the thresholds. They audit the edge cases. They decide what the model should escalate and what it can resolve. The AI doesn't replace them; it gives them leverage they've never had before.
This is better on every dimension that matters.
It's better for outcomes. The hardest decisions in safety aren't the high-volume ones—they're the novel ones, the ones where context determines everything. Those are exactly the decisions that BPO workflows have historically been worst at and that in-house experts are best at. Inverting the pyramid means concentrating human attention where human attention actually moves the needle, instead of spreading it thin across a torrent of low-stakes calls that a model can handle.
It's better economically. The honest TCO of a BPO arrangement—including vendor management, calibration overhead, quality assurance loops, policy translation cycles, attrition-driven retraining, and the legal and reputational exposure that comes with reviewer harm cases—has always been higher than the line-item cost suggested. A smaller, in-house, AI-leveraged team produces fewer of these hidden costs. You don't need a quality assurance program to audit your vendors when the vendor is a model you control and an expert you employ.
It's better ethically, and I want to be direct about this part because the industry has been evasive about it for a long time. The contractor-pyramid model of platform safety has been built on people doing some of the most psychologically punishing work in the modern economy for some of the lowest wages, with the least job security, and the least recourse when the work damages them. We knew this. We built workflows that minimized but never eliminated the exposure, because elimination wasn't possible at the volumes involved. Elimination is now possible. Refusing to pursue it—choosing instead to just make the pyramid cheaper—is a choice the industry will be judged for.
The objection I hear most often is that AI isn't reliable enough to take on this much of the review load. I think this objection confuses two different questions. AI is not reliable enough to operate unsupervised across the full range of T&S decisions—but I'd argue we wouldn't want that even if it were. But AI is absolutely reliable enough to operate under the supervision of an in-house expert who controls the system, monitors its decisions, and intervenes on the cases that warrant it. That's a fundamentally different operating posture than "AI replaces human review." It's AI as a force multiplier for the small number of people whose judgment you actually trust.
The other objection is that you can't hire that many subject matter experts (or that you can't afford to). This is empirically wrong—the pool of qualified clinicians, lawyers, compliance specialists, and policy experts is far larger than the pool of qualified content moderators, because these are established professions with established training pipelines. And if we're going to discuss cost, we need to compare against something. Against the visible cost of a BPO contract, in-house experts look expensive. Against the total cost of the contractor pyramid, including everything I listed above, the math is much less clear, and increasingly runs the other way.
We very intentionally built Moonbounce to support the future that is just now emerging and I think it's worth being explicit about why the tooling has to look different than what most T&S teams use today. If the subject matter expert is going to actually own the policy, they also need to be able to validate any updates against the metrics that matter before deploying a change. We also believe they should be able to push those updates to production without filing an engineering ticket and waiting a sprint. Tooling that keeps experts dependent on engineering for every iteration recreates the same distance problem the BPO pyramid had, just with a different intermediary. The whole point of bringing judgment in house is to close that loop.
The shape of the T&S team is going to change. The teams that move first will end up with deeper expertise, better tooling, lower long-run cost structures, and—not incidentally—a defensible answer when someone asks how the work gets done and who bears its costs.
